ジョブマッチングの為のword2vec
Qiitaから移行しました。
概要
求職者が仕事を探す時に、完全にスキルや職種名がマッチすることは多くはありません。 さらに表記揺れが多いこともあって、従来のキーワードマッチングで適切な求人を探すのは難しいのが現状です。
そこで今回、word2vecを使って求人によく使われる単語の意味を学習させてみました。 学習済みモデルから得られる類似するスキル名や職種名を使うことで、Semantic job search が可能になります。
word2vec とは
word2vecは単語をベクトル空間で表現する(word embeddings)ことができ、 これによって似たような単語を見つけたりやクラスタリングをすることが可能になります。
Word2vecやword embeddingsの詳細については他の方が説明されていますのでそちらを参考にしてください。
求人データ
今回はWeb上に公開されている求人データを使いました ジャンルはIT・Web業界に絞り、合計12130件のデータを集めました。
職種名、サマリー、応募資格 の項目を学習に使いました。

データ前処理
まずは、サマリーと応募資格をTokenizeして名詞のみを抽出しました。 (修飾語や動詞などは仕事の内容をあまり示していないので今回の学習からは省きました。)
抽出された単語はこんな感じで、web, アプリ開発, java など仕事内容を示すキーワードが抽出出来ていますね。
['学歴', '不問', 'web', 'アプリケーション', '領域', '開発', '経験', '方', '実務', '経験', 'プログラミング', '好き', 'アプリ開発', '好き', '方', '応募', 'java', 'javascript', 'css', 'html', '開発', '経験', '方', '優遇', '方', '歓迎', '自社', '内', '腰', '医方', 'アプリ開発', '好き', '方', 'ワーク・ライフ・バランス', '医方', '自分', '裁量', '状態', '医方', '社会貢献', '性', '高位', '仕事', '医方', 'エンドユーザー', '評価', '自分', '医方', '活', '経験', 'スキル', 'システム', 'アプリケーション', '開発', '経験', '当社', '開発', 'エンジニア', '一員', '活躍', '実務', '経験', '趣味', 'プログラミング', '遊び', 'ゲーム開発', '開発', '好き', '方', '一緒に', '有名', 'もの', 'java', 'javascript', 'css', 'html', '開発', '経験', '成長', '環境', '歓迎', '経験', 'スキル', 'プラットフォーム', '開発', '経験', 'ios', 'android', 'アプリケーション', '開発', '経験', 'google maps api', 'アプリケーション', '開発', '経験', 'agile', '開発', '経験']
次に職種名ですが、
webエンジニア, フロントエンジニアをtokenizeせずに個別の単語として取扱いました。
理由としては、各々の職種名の意味を学習させたかったからです。
クリーニング・正規化して、ある程度の表記揺れを解消しました。
Webエンジニア -> webエンジニア 【AIプロダクト】 Webエンジニア -> webエンジニア WEBエンジニア(リーダ候補) -> webエンジニア
トレーニング
今回はGensimのAPIを使って学習しました。
文章毎の単語の配列を与えるのですが、職種名の意味を学習させるために応募資格の最初の単語として追加しました。
['webエンジニア'] + ['必須', '条件', 'python', '開発', '経験', '機械学習', ...]
また、下記がトレーニングのパラメータになります
| 項目 | 値 |
|---|---|
| ベクターサイズ | 100 |
| ウインドウサイズ | 10 |
| アルゴリズム | CBOW |
結果
類似単語
いくつかの職種の類似単語を調べてみます。
similar_words('Webエンジニア') => [('サーバーサイドエンジニア', 0.8966489434242249), ('webアプリケーションエンジニア', 0.8889687061309814), ('開発エンジニア', 0.8835119009017944), ('フルスタックエンジニア', 0.8723335266113281), ('rubyエンジニア', 0.8664447069168091), ('サーバサイドエンジニア', 0.8570215702056885), ('web開発エンジニア', 0.8520206212997437), ('アプリケーションエンジニア', 0.8453050255775452), ('バックエンドエンジニア', 0.8452906608581543), ('railsエンジニア', 0.8418977856636047)]
similar_words('UIデザイナー') => [('ui・uxデザイナー', 0.9382747411727905), ('ui/uxデザイナー', 0.9307737350463867), ('webデザイナー/コーダー', 0.9097369313240051), ('ux/uiデザイナー', 0.9043135046958923), ('2dデザイナー', 0.903240442276001), ('webデザイナー・htmlコーダー', 0.8986614942550659), ('webクリエイター', 0.8866125345230103), ('エフェクトデザイナー', 0.8825030326843262), ('cgデザイナー', 0.8771432638168335), ('モーションデザイナー', 0.8738027811050415)]
similar_words('aiエンジニア') [('データエンジニア', 0.927179753780365), ('機械学習エンジニア', 0.9107803702354431), ('ai開発エンジニア', 0.9047583341598511), ('webシステム開発エンジニア', 0.90267014503479), ('webプログラマー', 0.891706109046936), ('製品開発エンジニア', 0.8902024626731873), ('webシステムエンジニア', 0.8894868493080139), ('se・pg', 0.8882736563682556), ('javaエンジニア', 0.8881719708442688), ('rd', 0.8856392502784729)]
ポピュラーなwebエンジニア, UIデザイナーの結果はとても納得感ありますね。
マイナーなAIエンジニアもそれなりに良い結果が返って来ています。
次に、スキル名の類似単語を見ていきます。
similar_words('Ruby') => [('php', 0.9285846948623657), ('perl', 0.8777764439582825), ('java', 0.8664125800132751), ('ruby on rails', 0.8557538986206055), ('python', 0.8433256149291992), ('elixir', 0.8411149978637695), ('symfony2', 0.8331097364425659), ('言語', 0.8303745985031128), ('web エンジニア', 0.8260266780853271), ('clojure', 0.8259769082069397)]
Rubyに対しては、同じくらいポピュラーなプログラミング言語やフレームワークが表示されました。
similar_words('photoshop') => [('illustrator', 0.9775387048721313), ('fireworks', 0.8953925967216492), ('dreamweaver', 0.8600867986679077), ('adobe illustrator', 0.8445886373519897), ('adobe photoshop', 0.8391222953796387), ('ui・uxデザイナー', 0.8321688175201416), ('webデザイナー/コーダー', 0.8211061954498291), ('webデザイナー・htmlコーダー', 0.8204653263092041), ('uiデザイナー', 0.815212607383728), ('indesign', 0.8117254376411438)]
photoshopとillustratorの類似度が他と比べてすごく高いですね。
Visualization
次にポピュラーな職種名のベクトルを2次元にマッピングしてみました。
Web系エンジニア

UIデザイナー、ディレクターなど

非エンジニア

結構いい感じにグループが出来ていますね。
まとめ
今回の結果から、求人に使われている職種名やスキルを学習できていることが確認できました。 次回は類似単語を使って、検索エンジンの結果を向上させてみたいと思います。 最後まで読んで頂き、ありがとうございました。
今回の検証に利用したコードやデータはGithubのレポジトリにありますので もし自分でも試して見たい方は参考にしてください。
Tensorflow Object Detection API クイックスタート
Qiitaから移行しました。
はじめに
この記事は2017年6月に公開されたTensorflow Object Detection APIのクイックスタートガイドです。 ドキュメント読んだり、環境設定に時間を掛けずにペットデータセットを使ったサンプルをDockerを使ってローカル環境で簡単に試せるようにしました。 僕自身もそうですが、普段PythonやDeepLearningをやっていない人の助けになれれば幸いです。
環境
必要な環境はDockerだけです。 メモリが足りないとプロセスが止まってしまうので12GB程度割り当てて下さい。
- Docker
- CPUs: 2, Memory: 12GB
Mac以外でも動くと思いますが、自分のマシンのスペックを記載しておきます。
- MacBook Pro (13-inch, 2016)
- CPU: 3.3 GHz Intel Core i7
- Memory: 16 GB
- OS: macOS Sierra 10.12.6
ステップ
Clone repository
まずはこのクイックスタートのために用意したレポジトリをクローンします。
git clone https://github.com/Jwata/tensorflow-pet-detector-quickstart cd tensorflow-pet-detector-quickstart
TF Recordの作成
ペットデータをダウンロードして、Object Detection APIのレポジトリのスクリプトを使ってTFRecordを作成します。 ダウンロードに結構時間かかります。
pushd data wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/annotations.tar.gz tar -xvf images.tar.gz tar -xvf annotations.tar.gz popd docker run -it -v `pwd`/data:/data jwata/tensorflow-object-detection \ python object_detection/create_pet_tf_record.py \ --label_map_path=/data/pet_label_map.pbtxt \ --data_dir=/data \ --output_dir=/data
dataディレクトリ内を確認して2つのファイルが出来ていればOKです。
pet_train.recordはトレーニング用、pet_val.recordは評価用に使います。
ls data/pet_*.record data/pet_train.record data/pet_val.record
学習済みモデルのダウンロード
COCOデータセットの学習済みモデルをダウンロードします。 モデルはチュートリアルで使われているFasterRcnn + Resnet101というものを使っていますが、Googleは他の種類の学習済みも公開しているので、Configファイルを変更すれば別のモデルを選択することも可能です。 モデルの違いについては現在勉強中です。
pushd data wget http://storage.googleapis.com/download.tensorflow.org/models/object_detection/faster_rcnn_resnet101_coco_11_06_2017.tar.gz tar -xvf faster_rcnn_resnet101_coco_11_06_2017.tar.gz cp faster_rcnn_resnet101_coco_11_06_2017/* . popd
トレーニング
Dockerを使ってトレーニングのプロセスを開始します。
docker run -d -v `pwd`/data:/data --name pet_detector_train jwata/tensorflow-object-detection \ python object_detection/train.py \ --logtostderr \ --pipeline_config_path=/data/faster_rcnn_resnet101_pets.config \ --train_dir=/data/train
評価
トレーニングを開始したら評価のプロセスも開始できます。
docker run -d -v `pwd`/data:/data --name pet_detector_eval jwata/tensorflow-object-detection \ python object_detection/eval.py \ --logtostderr \ --pipeline_config_path=/data/faster_rcnn_resnet101_pets.config \ --checkpoint_dir=/data/train \ --eval_dir=/data/eval
Tensorboard
トレーニングと評価の進捗をTensorboardで確認します。
docker run -d -v `pwd`/data:/data -p 6006:6006 --name tensorboard \ jwata/tensorflow-object-detection \ tensorboard --logdir=/data open http://localhost:6006
10分ほど待つと評価プロセスの結果の画像が表示されると思います! 2,3日夜通し計算して5000~7000ステップほど学習したら結構良い結果が出ていました。
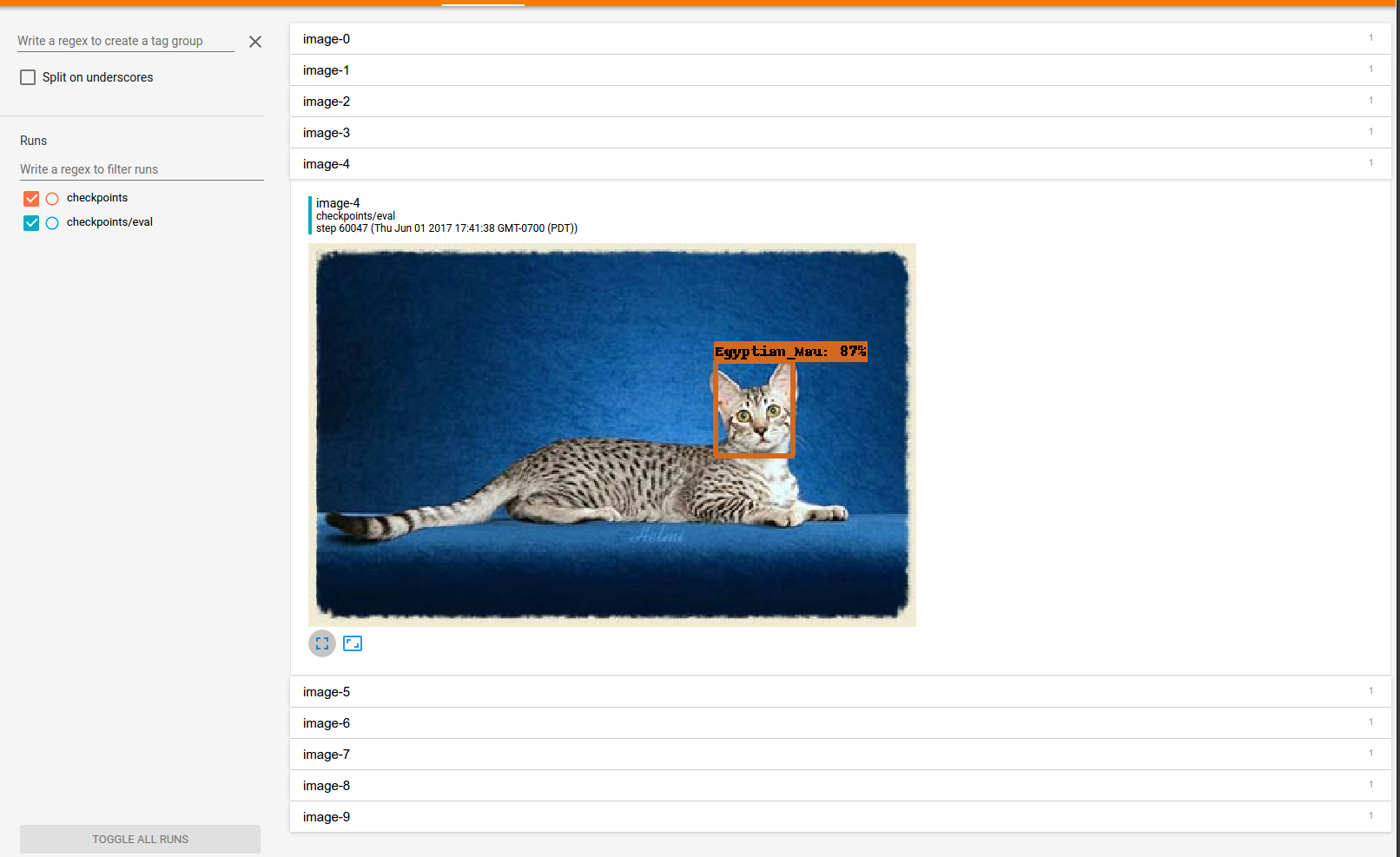
最後に
DeepLearningは勉強していてわくわくしますね。 次は下記のことを進めてていきます。
- 違うモデルで学習する
- 自分のデータセットで学習する
- 寿司の画像で学習中です。近日中に進捗を共有します。
参考リンク
Object Detection API のドキュメント(英語)
- Quick Start: Distributed Training on the Oxford-IIIT Pets Dataset on Google Cloud
- Running Locally
- ObjectDetectionAPIをローカルマシンで使うための解説
- Configuring the Object Detection Training Pipeline
- トレーニングのConfigについて
他の解説記事
RailsでのCSRF token 発行 / 検証のロジック
RailsでのCSRF対策
RailsではdefaultでFormHelperやjquery-railsによりauthenticity tokenをリクエストに追加して送り、サーバーで検証するというCSRF対策がされています。rails csrfと検索すると関連するページがたくさん見つかります。
今回は普段は気にしなくても良い、token発行や検証の仕組みを確認してみました。
ソースコード
ロジックはすべてAction Packのrequest_forgery_protection.rbに実装されていて、実際にコードを確認しました。
Authenticity Token 発行
まずはToken発行の仕組みを見ていきます。
form_authenticity_tokenというhelper methodがviewからアクセスできるようになっており、tokenを発行するインターフェースとなっており、その中で呼ばれているmasked_authenticity_tokenでtokenの発行ロジックが記述されています。
def masked_authenticity_token(session, form_options: {}) # :doc: action, method = form_options.values_at(:action, :method) raw_token = if per_form_csrf_tokens && action && method action_path = normalize_action_path(action) per_form_csrf_token(session, action_path, method) else real_csrf_token(session) end one_time_pad = SecureRandom.random_bytes(AUTHENTICITY_TOKEN_LENGTH) encrypted_csrf_token = xor_byte_strings(one_time_pad, raw_token) masked_token = one_time_pad + encrypted_csrf_token Base64.strict_encode64(masked_token) end
raw_token
... raw_token = if per_form_csrf_tokens && action && method action_path = normalize_action_path(action) per_form_csrf_token(session, action_path, method) else ...
per_form_csrf_tokenを見ると、セッションに保存されたcsrf tokenとaction, method を組み合わせてSHA256 ハッシュを作成しています。これが raw_tokenとして使われています。
session[:_csrf_token]
def real_csrf_token(session) # :doc: session[:_csrf_token] ||= SecureRandom.base64(AUTHENTICITY_TOKEN_LENGTH) Base64.strict_decode64(session[:_csrf_token]) end
raw_tokenの計算に使われるsassion[:_csrf_token]はSecureRandom.base64で作られたランダムな文字列が保存されていて、同じものを同じセッションで使い回されていてます。
masked_token
... one_time_pad = SecureRandom.random_bytes(AUTHENTICITY_TOKEN_LENGTH) encrypted_csrf_token = xor_byte_strings(one_time_pad, raw_token) masked_token = one_time_pad + encrypted_csrf_token ...
生成されたraw_tokenとone_time_padを合わせてmasked_tokenが生成されています。
one_time_padはraw_tokenと同じ長さのランダムなバイト列で、xor_byte_stringsというmethodでraw_tokenにマスクするのに使われています。このmethodは検証にも使われます。
authenticity token
...
Base64.strict_encode64(masked_token)
end
masked_tokenをbase64でencodeしたものがauthenticity tokenとして、HTMLページに埋め込まれます。
Authenticity Token 検証
次にToken検証のロジックを見ていきます。
全てのリクエストはbefore_actionでverify_authenticity_tokenが実行されていて、authenticity tokenの検証が必要なリクエストに対して検証ロジックが実行されます。
ロジック自体はvalid_authenticity_token?に記述されています。
def valid_authenticity_token?(session, encoded_masked_token) # :doc: ... begin masked_token = Base64.strict_decode64(encoded_masked_token) rescue ArgumentError # encoded_masked_token is invalid Base64 return false end if masked_token.length == AUTHENTICITY_TOKEN_LENGTH compare_with_real_token masked_token, session elsif masked_token.length == AUTHENTICITY_TOKEN_LENGTH * 2 csrf_token = unmask_token(masked_token) compare_with_real_token(csrf_token, session) || valid_per_form_csrf_token?(csrf_token, session) else false # Token is malformed. end end
decode token
masked_token = Base64.strict_decode64(encoded_masked_token)
まずはリクエストで送られてきたtokenをBase64でdecodeします
unmasked tokenの場合
if masked_token.length == AUTHENTICITY_TOKEN_LENGTH compare_with_real_token masked_token, session elsif masked_token.length == AUTHENTICITY_TOKEN_LENGTH * 2 ...
masked_tokenという変数名ですが、長さがAUTHENTICITY_TOKEN_LENGTHと同じ場合はmaskされていないものとして、セッション内に保存されたcsrf tokenと直接比較しています。
masked tokenの場合
elsif masked_token.length == AUTHENTICITY_TOKEN_LENGTH * 2 csrf_token = unmask_token(masked_token) compare_with_real_token(csrf_token, session) || valid_per_form_csrf_token?(csrf_token, session) else ...
変数masked_tokenの長さがAUTHENTICITY_TOKEN_LENGTHの2倍の場合は、maskされているものとして、unmask_tokenをしてから、compare_with_real_token実行されています。
unmask_token
def unmask_token(masked_token) # :doc: # Split the token into the one-time pad and the encrypted # value and decrypt it. one_time_pad = masked_token[0...AUTHENTICITY_TOKEN_LENGTH] encrypted_csrf_token = masked_token[AUTHENTICITY_TOKEN_LENGTH..-1] xor_byte_strings(one_time_pad, encrypted_csrf_token) end
コメントにあるように、tokenを半分に分割します。
ここでxor_byte_stringsにone_time_padとencrypted_csrf_tokenを実行することで、encrypted_csrf_tokenのmaskを外しています。
maskが外されたcsrf_tokenとセッション内に保存されたcsrf tokenを比較して一致するか比較しています。
Demo
ロジックがわかれば、HTMLページ内のauthenticity_tokenからセッションに保存されている CSRF tokenが計算することができます。
https://gist.github.com/Jwata/4e5122fa43d719400914716955872cc2
> git clone https://gist.github.com/Jwata/4e5122fa43d719400914716955872cc2 authenticity_token_to_csrf_token > rails runner ./authenticity_token_to_csrf_token/calculate.rb 'S5O27L72mhZRQk4rP16sIbj2m0BI7SrujJyh+hEXoaeTaT6GHxXx6d7UFnU05z6VxWFgb4wG+AtFsuHb5mqQ/A==' => 2PqIaqHja/+PllheC7mStH2X+y/E69LlyS5AIfd9MVs= > rails runner ./authenticity_token_to_csrf_token/calculate.rb 'JU6qRx/avhFPb/8+F3oZl/Iabr3nSbWVIgSHPm0Bz9n9tCItvjnV7sD5p2Acw4sjj42VkiOiZ3DrKscfmnz+gg==' => 2PqIaqHja/+PllheC7mStH2X+y/E69LlyS5AIfd9MVs=
この場合は2PqIaqHja/+PllheC7mStH2X+y/E69LlyS5AIfd9MVs=がsession[:_csrf_token]の値です。
関連ページ
英語が苦手な僕が、インターナショナルなチームで働いてて思ったこと。
現在の職場は、日系の企業だけどチームのメンバーなみんな外国の人でコミュニケーションは主に英語を使っています。
僕は学生の時、本当に英語が苦手で TOEIC400点以下だったと思います。 なので今こうした状況にいるのは不思議です。
3年ぶりにブログを書くのは、 たまに無性に日本語が恋しくなるので、ストレス発散になるかなと思たからです。笑
今も英語は得意じゃないから、仕事でいつも困ってはいますが、エンジニアとしてインターナショナルな環境に身をおくことについていくつかメリット、デメリットを書きたいと思います。
メリットはよく言われていることだと思います
メリット1 英語学習のモチベーション エンジニアの方ならその重要性を感じていると思いますが、 プログラミングやシステム開発の情報は英語が圧倒的に多く、オープンソースのプロジェクトの議論も英語でされています。 ただ、前職の時はほぼ勉強はしていなかったです 必要性や危機感を感じてやっと少しずつ勉強するようになりました。
メリット2 キャリアの幅が広がる これもよく言われることではありますが 今東京だとインターナショナルなチームの募集が結構あって 今後も増えて行くと思っています。
選択の幅が広がると何が嬉しいかというと、 チームの雰囲気や使ってる技術や働き方や給料などを比較できるからです。
メリット3 違う価値観を学べる 残業や休みに対する考え方や、リモートワークや新しいやり方を取り入れることにオープンです。 ここが一番大きかったと感じていて、 日本人の中だと自分勝手とか変わってるって言われてることも、みんなが納得すれば受け入れられる雰囲気です。
でもこれは多分会社によってて 大きい会社や、トップダウンの会社では状況が違うかもしません。
次にデメリットになります。
デメリット1 言葉が通じない! 毎日毎日、自分の伝えたいことが伝えられないのは本当にストレスです。。救いとしてはみんな日本に興味があるから東京にいるので、好意的だし、日本語しゃべれる人も多いです。 あとは仕事以外では普通に日本語使えるので、そのぶん海外勤務とかより断然ストレスは低いと思います。
デメリット2 議論が長い とにかくみんな議論が好きで、1つのことに合意するのが大変です。英語力の問題もあってヘトヘトになります。 ただ、それだけみんな自分の意見があるということなんですね。
もともと自分も頑固なので、ハッキリものが言える環境にいるのは良いなと感じます。 興味がある人は、条件が合えば是非チャレンジした方が良いと思います!
リーンスタートアップを読んで その3
リーンスタートアップ読み終わりました。
普段開発をしていて、もっと効率よくサービス開発出来ないのかと自問していたけど、
方向性が見れた気がします。
第3章 スピードアップ
この辺は、実際にスタートアップをやっている中で重要なことだと思うので、
印象に残ったところをピックアップします。
5回のなぜ
ミスや障害が起きた時に、個別の事象や個人を非難するのではなく、
それが起きた仕組みに問題があるので根本的な解決をしようとする試み。
これは業務でも活かせそうで 、本文にもある通り
「この状況にもう一度陥らないためにはどうすればいいだろうか」
と自問自答することから始められそう。
実際に、特に開発フローを上手く改善出来たときは、こういう考えが出来てて 。 誰かがミスが多かったりボトルネックだったりして、悶々とする時は、システムとしての欠陥に気づけてい無い時だなと感じました。
まとめ
3章も内容的にはとても勉強になったけど、特に5回のなぜは重要なだなと思いました。
今後、ユーザーに価値を効率化よく届ける為のサービス開発に活かして行きたいと思います。
リーンスタートアップを読んで その2
最近読んでいるリーンスタートアップの備忘録
内容
舵取り
始動
スタートアップの事業計画は仮説に基いており、その検証を行うことが立ち上げ時の目標となる。 「評価尺度の実体は人である」と言われているように、実際の顧客にあってその仮説が正しいか確認してくことが重要である。と述べている。
構築・検証
リーンスタートアップでMVPと呼ばれる、仮説を検証できる実用最小限の製品を構築して、実際に見込み客のフィードバックを得るべきだと述べている。
現職のゲーム開発では、このへんの取り組みが出来ていないなと感じた。
簡単なモックを作って、ユーザーテストをして。といったサイクルは出来ないわけではないのに。。
これはチーム内でも、会社内の公開を通してでも良いので、
作ろうとしているゲームが本当に面白いのかを、本開発の前にきちんと確認しないといけないと感じた。
(α開発は1ヶ月くらいで出来るけど、本開発は4ヶ月くらいかかってしまうから。)
フラッシュエンジニアとプロデューサーだけでこの試行は出来る気がする。
計測
一般的な管理会計では、スタートアップを正当に評価できないので、行動につながる評価基準を持ち、広告などによってつくるのことの出来る虚栄の評価基準を見て判断してはいけない。
評価の尺度はコホート型にし、新機能の投入はスプリットテスト(A/Bテスト)で確認することで、顧客が本当に望んでいるのは何であるのか学習するサイクルにすることを提案している。
また1つの開発は検証による学びを得られてはじめて完結だと考えることが重要だと述べている。
以前海外向けのゲームプロダクトを運営していた時、とにかくチュートリアルの突破率が高く、A/Bテストを軸に導線や遷移改善を繰り返し行なったことを思い出した。
「スマホのファーストビューに押して欲しいボタンが入っているか」「このページは無くせるのではないか」1つ1つは単純でちいさな仮説であったけど、結果としてチュートリアルの突破率を10%以上高めることができた。 これはまさに必要なことだったと再認識しました。
この辺は実際に運用や開発をしているからわかるけど、そもそも仕組み化しないと計測のコストがいちいち掛かるので、 機能のA/Bの出し分け -> 計測 -> グラフ化 までを自動で出来るようになっていると良いなと思った。
方向転換
事例を踏まえて、スタートアップの方向性を変更するか、辛抱するかの判断について述べている。
この辺りは、スタートアップにチャレンジしたことが無いのでわからないが、
恐らく実際にこの状況になったときに方向転換できるのか、また辛抱するのかの決断を冷静に勇気を持って行えるかが重要だと思う。
まとめ
自分のプロダクト運営の経験の中でも実感として分かる部分と、参考にしなければいけない部分があり、
非常に重要な章だなと思いました。
仕事を続けていく上で、繰り返し読み返したいと思います。
リーンスタートアップを読んで その1
はじめに
以前から気になっていたリーンスタートアップを読みはじめました。
スタートアップだけではなく、企業の中での新規事業、新サービスの開発にも参考になるなーと感じました
今までのサービス開発の中で出来ていたことや出来ていなかったこと、 今すぐにでも活用出来そうな手法が書いてあったので、
読み途中ですが、備忘録としてブログにしたいと思います。
内容
ビジョン
スタート
この章では、この本の主題である「起業とはマネジメントである」ことと、起業を一般のマネジメント手法を適用することは相性が悪く、従来とは異なる方法で生産性を測る必要がある ことが書かれている。
新規事業を立ち上げ、新たな売上の柱を作りたい企業はたくさんあるが、その進捗は売上による利益貢献によって見ようとしていて、プロジェクトの継続・中止の判断やプロジェクトの評価に悩んでいる企業が多い気がする。
新規事業に関する生産性の測り方、継続・中止あるいは方向転換の判断をどうするべきなのか疑問に思っていたので読み進めることにしました。
定義
アントレプレナーとはどいういう人を指すのか、本書の中での定義や事例の紹介がおこなれている
学び
スタートアップが行うべきなのは、自分たちがたてた戦略や仮説を検証により学びを得ることだと。
それに対して過大な労力や見当外れの頑張りをしてしまった失敗も交えて書かれている。
実験
スタートアップの実験で検証すべきなのは、下記2点である
価値仮説
仮説となるサービスが提供出来たとき、ユーザーが本当に価値を感じてサービスを利用してくれるかどうか 確認する
成長仮説
最初のアーリーアダプターがどのように広まっていくか、サービスを体験したユーザーが他のユーザーを誘ってくれると仮説をたてた場合、本当にそれがなされているのか確認する
この章もたくさんの事例を用いて実験の説明がされている。
まとめ
ちょっと長くなってきたので、この辺でやめたいと思います。
起業・スタートアップとはマネジメントであり、自分の仮説を検証するために実験をするのだという捉え方が書いてあり、漠然としたスタートアップのイメージがクリアになりました。
具体的なものに対してだったら、頑張れる優秀な人はたくさんいると思っているので、
こういった手法が浸透してスタートアップに取り組む人達のエネルギーが無駄にならない時代を作っていきたいと思いました。